
Highlighted publication on Persyst 14 and its Seizure Detector
The release of Persyst 14 and its Seizure Detector was accompanied by the publication, “Seizure Detection: Interreader Agreement and Detection Algorithm Assessments Using a Large Dataset.”
This publication accomplished two things:
First, it established interreader agreement in a real-world environment. Three board certified neurophysiologists marked 120 prolonged (24-hour) EEGs for seizures. Marking was completely independent and without consensus discussions. The dataset was minimally selected and contained a mix of 100 consecutive seizure-containing records mixed with 20 seizure-free (though not necessarily normal) records.
In this study, the human experts achieved an average pairwise* sensitivity of 77% and a false-positive rate of 0.8 per day.
Pairwise* measurement of sensitivity and false positive rates across multiple readers is a statistical test, ultimately calculating the likelihood any two readers will agree with each other.
Additionally, compared to the previous studies that assessed interreader agreement,
In fact, this study likely reflects the high-end of interreader agreement that would be found in an EMU environment. The readers were not facing significant time constraints, and they were aware that their markings would be compared with other experts. This would actually favor more thorough and considered marking rather than the standard clinical review setting, where reading time is more constrained, distractions are more prevalent, and fatigue is common.
Second, after establishing the average interreader agreement, the study then assessed the pairwise human-algorithm performance of two seizure detection algorithms (P13 and P14) compared to the human experts, (i.e., P13 and P14 were compared with readers A, B, and C).
By treating the algorithms exactly the same as the human readers, the study could directly assess whether the algorithms performed within the range of the human experts.
The results showed the P14 seizure detector is statistically non-inferior to the performance of this study’s expert readers. The performance of the older P13 seizure detection algorithm did not approach that of the human experts because of a much higher false-positive rate.
More specifically, P14 had a pairwise sensitivity of 78.2% and a false-positive rate of 0.9 per day, which is within the range of the human experts in this study.
The algorithm will be quite useful as an adjunct to the existing visual observation methods of seizure identification, sometimes enabling earlier seizure recognition, improving review efficiency, and enhancing overall seizure recognition.
While this may be an impressive achievement, where notably both the spike and seizure detector algorithms in Persyst 14 are found to be statistically non-inferior to expert human readers, the work is certainly not done.
Our aim at Persyst is to continue to push the edges of what is possible by developing additional metrics to keep improving the detection algorithm’s performance.
Other interesting findings: The performance of the older P13 seizure detection algorithm did not approach that of human experts, despite having a pairwise sensitivity of 82.5%, due to a much higher false positive rate (11.3 per day). Set to a higher sensitivity equivalent to the P13 sensitivity, the P14 detector produces 2.3 false positives per day.
The standard pairwise comparison compares the performance of the algorithm to one human expert. If a subset of seizure data is considered, where two readers were in agreement regarding the presence of a seizure, a third reader was more likely to also identify such events as seizures. Readers averaged a sensitivity of 89% for these consensus-of-two events. The P14 seizure detector demonstrated a sensitivity of 89.7% for the same-consensus-of-two seizures. When evaluated against the smaller subset of seizures marked by all readers (consensus-of-three), the P14 algorithm had a sensitivity of 90% with a false positive rate of about one per day. Finally, if, during clinical review, a P14 detection algorithm sensitivity was chosen that resulted in an average of four false positives per day, the sensitivity for consensus-of-three seizure events would be 98.5% in this dataset. This shows that using the new adjustable features of P14 sensitivity virtually all seizures in this data set were marked with what many would consider to be a reasonable number of false positives during review.
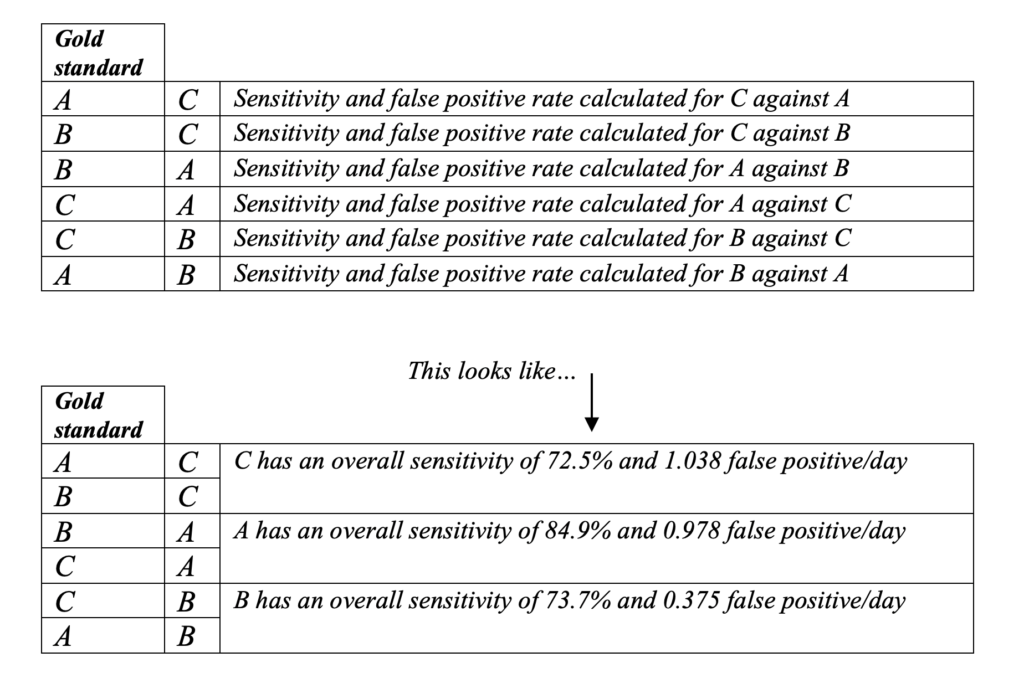
*Pairwise sensitivity means that every possible pair combination of readers is assessed where one reader’s marks is considered the gold standard and the sensitivity and false positive rate is calculated for the other and vice versa (see tables below). This is a statistical test, and rather than establishing “ground truth”, this is instead a calculation of the likelihood that any two expert readers will agree with one another.
This method also makes it possible to assess a detection algorithm in exactly the same way the expert readers were assessed, making it possible to say how likely the algorithm and a human reader will “agree” with one another. In the chart below A, B, and C identify each reader.
Publications from Persyst
- Koren, J., Colabrese, K., Hartmann, M., Feigl, M., Lang, C., Hafner, S., Nierenberg, N., Kluge, T., Baumgartner, C. “Systematic comparison of Commercial seizure detection Software: Update equals Upgrade?” Clinical Neurophysiology 174 (June 2025): 178-188. https://www.sciencedirect.com/science/article/abs/pii/S1388245725005632
- Scheuer, M.L., Wilson, S.B., Antony, A., Ghearing, G., Urban, A., Bagic, A.I. “Seizure Detection: Interreader Agreement and Detection Algorithm Assessments Using a Large Dataset.” J Clin Neurophysiol 00 (May 2020): 1-9. https://dx.doi.org/10.1097/WNP.0000000000000709
- Joshi, C. N., K. E. Chapman, J. J. Bear, S. B. Wilson, D. J. Walleigh, and M. L. Scheuer. “Semiautomated Spike Detection Software Persyst 13 Is Noninferior to Human Readers When Calculating the Spike-Wave Index in Electrical Status Epilepticus in Sleep.” J Clin Neurophysiol 35, no. 5 (Sep 2018): 370-74. https://dx.doi.org/10.1097/WNP.0000000000000493.
- Scheuer, M. L., A. Bagic, and S. B. Wilson. “Reply To “What It Should Mean for an Algorithm to Pass a Statistical Turing Test for Detection of Epileptiform Discharges”.” Clin Neurophysiol 128, no. 7 (07 2017): 1408-09. https://dx.doi.org/10.1016/j.clinph.2017.03.006.
- Scheuer, M. L., A. Bagic, and S. B. Wilson. “Spike Detection: Inter-Reader Agreement and a Statistical Turing Test on a Large Data Set.” Clin Neurophysiol 128, no. 1 (Jan 2017): 243-50. https://dx.doi.org/10.1016/j.clinph.2016.11.005.
- Wilson, S. B. “Spike Detection Algorithm Performance and Methods of Acquiring Expert Opinion.” Clin Neurophysiol 121, no. 11 (Nov 2010): 1968-9; author reply 68. https://dx.doi.org/10.1016/j.clinph.2010.04.012.
- Wilson, S. B. “Algorithm Architectures for Patient Dependent Seizure Detection.” Clin Neurophysiol 117, no. 6 (Jun 2006): 1204-16. https://dx.doi.org/10.1016/j.clinph.2006.02.014.
- Wilson, S. B. “A Neural Network Method for Automatic and Incremental Learning Applied to Patient-Dependent Seizure Detection.” Clin Neurophysiol 116, no. 8 (Aug 2005): 1785-95. https://dx.doi.org/10.1016/j.clinph.2005.04.025.
- Wilson, S. B., M. L. Scheuer, R. G. Emerson, and A. J. Gabor. “Seizure Detection: Evaluation of the Reveal Algorithm.” Clin Neurophysiol 115, no. 10 (Oct 2004): 2280-91. https://dx.doi.org/10.1016/j.clinph.2004.05.018.
- Wilson, S. B., M. L. Scheuer, C. Plummer, B. Young, and S. Pacia. “Seizure Detection: Correlation of Human Experts.” Clin Neurophysiol 114, no. 11 (Nov 2003): 2156-64. https://dx.doi.org/10.1016/S1388-2457(03)00212-8.
- Wilson, S. B., and R. Emerson. “Spike Detection: A Review and Comparison of Algorithms.” Clin Neurophysiol 113, no. 12 (Dec 2002): 1873-81.
- Guess, M. J., and S. B. Wilson. “Introduction to Hierarchical Clustering.” J Clin Neurophysiol 19, no. 2 (Apr 2002): 144-51.
- Wilson, S. B., C. A. Turner, R. G. Emerson, and M. L. Scheuer. “Spike Detection Ii: Automatic, Perception-Based Detection and Clustering.” Clin Neurophysiol 110, no. 3 (Mar 1999): 404-11.
- Wilson, S. B., R. N. Harner, F. H. Duffy, B. R. Tharp, M. R. Nuwer, and M. R. Sperling. “Spike Detection. I. Correlation and Reliability of Human Experts.” Electroencephalogr Clin Neurophysiol 98, no. 3 (Mar 1996): 186-98.
Selected research publications utilizing Persyst
- Duckworth, E., Motan, D., Howse, K., Boyd, S., Pressler, R., Chalia, M. “Diagnostic Accuracy of the Persyst Automated Seizure Detector in the Neonatal Population.” J. Integr. Neurosci. (2024). https://www.imrpress.com/journal/JIN/23/8/10.31083/j.jin2308150
- Veciana de las Heras, M., Sala-Padro, J., Pedro-Perez, J., Garcia-Parra, B., Hernandez-Perez, G., and Falip, M. “Utility of Quantitative EEG in Neurological Emergencies and ICU Clinical Practice.” Brain Sciences (2024). https://www.mdpi.com/2076-3425/14/9/939
- Keene, J. C., Benedetti, G. M., Tomko, S. R., Guerriero, R. M. “Quantitative EEG in the neonatal intensive care unit: Current application and future promise.” Annals of the Child Neurology Society (2023). https://onlinelibrary.wiley.com/doi/full/10.1002/cns3.20042
- Reus, E. E. M, G. H. Visser and F. M. E. Cox. “Using sampled visual EEG review in combination with automated detection software at the EMU.” Seizure: European Journal of Epilepsy (June 2020). https://doi.org/10.1016/j.seizure.2020.06.002
- Kang, J.H., Sherill, G.C., Sinha, S.R., Swisher, C.B. “A Trial of Real-Time Electrographic Seizure Detection by Neuro-ICU Nurses Using a Panel of Quantitative EEG Trends.” Neurocritical Care (Feb 2019). https://doi.org/10.1007/s12028-019-00673-z
- Kamitaki, B.K., Tu, B., Reynolds, A.S., Schevon, C.A. “Teaching NeuroImages: Acute stroke captured on EEG in the ICU.” Neurology (Feb 2019): 92::e626-e627. https://doi.org/10.1212/WNL.0000000000006882
- Din, F., S. L. Ganesan, T. Akiyama, C. P. Stewart, A. Ochi, H. Otsubo, C. Go and C. D. Hahn. “Seizure Detection Algorithms in Critically Ill Children: A Comparative Evaluation.” Critical Care Medicine (Dec 2019). https://10.1097/CCM.0000000000004180
- Reus, E. E. M., G. H. Visser and F. M. E. Cox. “Determining the Spike-Wave Index Using Automated Detection Software.” Journal of Clinical Neurophysiology (Dec 2019). https://dx.doi.org/10.1097/WNP.0000000000000672
- Goenka, A., Boro, A., Yozawitz, E. “Comparative sensitivity of quantitative EEG (QEEG) spectrograms for detecting seizure subtypes.” Seizure (Jan 2018) 55:70-75. https://doi.org/10.1016/j.seizure.2018.01.008
- Sharpe, C., S. L. Davis, G. E. Reiner, L. I. Lee, J. J. Gold, M. Nespeca, S. G. Wang, P. Joe, R. Kuperman, M. Gardner, J. Honold, B. Lane, E. Knodel, D. Rowe, M. R. Battin, R. Bridge, J. Goodmar, B. Castro, M. Rasmussen, K. Arnell, M. Harbert, and R. Haas. “Assessing the Feasibility of Providing a Real-Time Response to Seizures Detected with Continuous Long-Term Neonatal Electroencephalography Monitoring.” J Clin Neurophysiol (Oct 2018). https://dx.doi.org/10.1097/WNP.0000000000000525.
- Halford, J. J., M. B. Westover, S. M. LaRoche, M. P. Macken, E. Kutluay, J. C. Edwards, L. Bonilha, G. P. Kalamangalam, K. Ding, J. L. Hopp, A. Arain, R. A. Dawson, G. U. Martz, B. J. Wolf, C. G. Waters, and B. C. Dean. “Interictal Epileptiform Discharge Detection in EEG in Different Practice Settings.” J Clin Neurophysiol 35, no. 5 (Sep 2018): 375-80. https://dx.doi.org/10.1097/WNP.0000000000000492.
- Drohan, C. M., A. I. Cardi, J. C. Rittenberger, A. Popescu, C. W. Callaway, M. E. Baldwin, and J. Elmer. “Effect of Sedation on Quantitative Electroencephalography after Cardiac Arrest.” Resuscitation 124 (March 2018): 132-37. https://dx.doi.org/10.1016/j.resuscitation.2017.11.068.
- Haider, H.A., Esteller, R., Hahn, C.D., Westover, M.B., Halford, J.J., Lee, J.W., Shafi, M.M., Gaspard, N., Herman, S.T., Gerard, E.E., Hirsch, L.J., Ehrenberg, J.A., LaRoche, S.M. “Sensitivity of quantitative EEG for seizure identification in the intensive care unit.” Neurology (Aug 2016): 87(9):935-944. https://doi.org/10.1212/WNL.0000000000003034
- Elmer, J., J. J. Gianakas, J. C. Rittenberger, M. E. Baldwin, J. Faro, C. Plummer, L. A. Shutter, C. L. Wassel, C. W. Callaway, A. Fabio, and Pittsburgh Post-Cardiac Arrest Service. “Group-Based Trajectory Modeling of Suppression Ratio after Cardiac Arrest.” Neurocrit Care 25, no. 3 (Dec 2016): 415-23. https://dx.doi.org/10.1007/s12028-016-0263-9.
- Schomer, A.C., Hanafy, K. “Neuromonitoring in the ICU.” International Anesthesiology Clinics (2015): 53(1):107-122. doi:10.1097/AIA.0000000000000042
- Swisher, C. B., C. R. White, B. E. Mace, K. E. Dombrowski, A. M. Husain, B. J. Kolls, R. R. Radtke, T. T. Tran, and S. R. Sinha. “Diagnostic Accuracy of Electrographic Seizure Detection by Neurophysiologists and Non-Neurophysiologists in the Adult ICU Using a Panel of Quantitative EEG Trends.” J Clin Neurophysiol 32, no. 4 (Aug 2015): 324-30. https://dx.doi.org/10.1097/WNP.0000000000000144.
- Fürbass, F., P. Ossenblok, M. Hartmann, H. Perko, A. M. Skupch, G. Lindinger, L. Elezi, E. Pataraia, A. J. Colon, C. Baumgartner, and T. Kluge. “Prospective Multi-Center Study of an Automatic Online Seizure Detection System for Epilepsy Monitoring Units.” Clin Neurophysiol126, no. 6 (Jun 2015): 1124-31. https://dx.doi.org/10.1016/j.clinph.2014.09.023.
- Sierra-Marcos, A., M. L. Scheuer, and A. O. Rossetti. “Seizure Detection with Automated EEG Analysis: A Validation Study Focusing on Periodic Patterns.” Clin Neurophysiol 126, no. 3 (Mar 2015): 456-62. https://dx.doi.org/10.1016/j.clinph.2014.06.025.
- Williamson, Craig A., Sarah Wahlster, Mouhsin M. Shafi, and M. Brandon Westover. “Sensitivity of Compressed Spectral Arrays for Detecting Seizures in Acutely Ill Adults.” Neurocritical Care20, no. 1 (February 2014): 32–39. https://doi.org/10.1007/s12028-013-9912-4.
Selected research publications on EEG Electrical Source Imaging (ESI)
- Vorderwülbecke BJ, Baroumand AB, Spinelli L, Seeck M. van Mierlo P, Vulliémoz S. Automated interictal source localization based on high-density EEG. Seizure. (2021) 92:244-251.
- Beniczky S, Trinka E. Editorial: Source Imaging in Drug Resistant Epilepsy – Current Evidence and Practice. Frontiers in Neurology. (2020). 11(56).
- Foged MT, Martens T, Pinborg LH, Hamrouni N, Litman M, Rubboli G, et al. Diagnostic added value of electrical source imaging in presurgical evaluation of patients with epilepsy: A prospective study. Clin Neurophys. (2020) 131:324-329.
- Coito A, Biethahn S, Tepperberg J, Carboni M, Roelcke U, Seeck M, et al. Interictal epileptogenic zone localization in patients with focal epilepsy using electric source imaging and directed functional connectivity from low-density EEG. Epilepsia. (2019). 4(2):281-292.
- Duez L, Tankisi H, Hansen PO, Sidenius P, Sabers A, Pinborg LH, et al. Electromagnetic source imaging in presurgical workup of patients with epilepsy. Neurology. (2019). 92: 576-586.
- Sharma P, Seeck M, Beniczky S. Accuracy of Interictal and Ictal Electric and Magnetic Source Imaging: A Systematic Review and Meta-Analysis. Frontiers in Neurology. (2019) 10:1250
- Baroumand AG, van Mierlo P, Strobbe G, Pinborg LH, Fabricius M, Rubboli G, et al. Automated EEG source imaging: A retrospective, blinded clinical validation study. Clin Neurophysi. (2018) 129:2403-2410.
- Sharma P, Scherg M, Pinborg LH, Fabricius M, Rubboli G, Pedersen B, et al. Ictal and interictal electric source imaging in pre-surgical evaluation: a prospective study. European Journal of Neurology. (2018). 25(9):1154-1160.
- Tatum WO, Rubboli G, Kaplan PW, Mirsatari SM, Radhakrishnan K, Gloss D, et al. Clinical utility of EEG in diagnosing and monitoring epilepsy in adults. Clinical Neurophysiology. (2018) 129:1056-1082.
- van Mierlo P, Strobbe G, Keereman V, Birot G, Gadeyne S, Gschwind M, et al. Automated long-term EEG analysis to localize the epileptogenic zone. Epilepsia. (2017). 2(3): 322-333.
- Mālîia MD, Meritam P, Scherg M, Fabricius M, Rubboli G, Mîndrutā I, Beniczky S. Epileptiform discharge propagation: Analyzing spikes from the onset to the peak. Clin Neurophys. (2016).
- Russo A, Lallas M, Jayakar P, Miller I, Hyslop A, Dunoyer C, et al. The diagnostic utility of 3D-ESI rotating and moving dipole methodology in the pre-surgical evaluation of MRI-negative childhood epilepsy due to focal cortical dysplasia. Epilepsia. (2016). 57:1450-1457.
- Park CJ, Seo JH, Kim D, Abibullaev B, Kwon H, Lee YH, et al. EEG Source Imaging in Partial Epilepsy in Comparison with Presurgical Evaluation and Magnetoencephalography. J Clin Neurology. (2015). 4:319-330.
- Rikir E, Koessler L, Gavaret M, Bartolomei F, Colnat-Coulbois S, Vignal JP, et al. Electrical source imaging in cortical malformation-related epilepsy: A prospective EEG-SEEG concordance study. Epilepsia (2014) 55(6):918-932.
- Megevand P, Vulliémoz S. Electric and Magnetic Source Imaging of Epileptic Activity. Epileptologie. (2013). 30:122-130.
- Coutin-Churchman PE, Wu JY, Chen LLK, Shattuck K, Dewar S, Nuwer MR. Quantification and localization of EEG interictal spike activity in patients with surgically removed epileptogenic foci. Clin Neurophys. (2012). 123:471-485.
- Lascano AM, Vulliemoz S, Lantz G, Spinelli L, Michel C, Seeck M. A Review on Non-Invasive Localisation of Focal Epileptic Activity Using EEG Source Imaging. Epileptologie. (2012). 29:80-89.
- Brodbeck V, Spinelli L, Lascano AM, Wissmeier M, Vargas MI, Vulliemoz S, et al. Electroencephalographic source imaging: a prospective study of 152 operated epileptic patients. Brain. (2011). 134:2887-2897.
- Bast T, Oezkan O, Rona S. Stippich C, Seitz A, Rupp A, Fauser S, et al. EEG and MEG Source Analysis of Single and Averaged Interictal Spikes Reveals Intrinsic Epileptogenicity in Focal Cortical Dysplasia. Epilepsia. (2004). 45:621-631.
- Michel CM, Murray MM, Lantz G, Gonzalez S, Spinelli L, Grave de Peralta R. An Invited Review: EEG Source Imaging. Clinical Neurophysiology. (2004). 115: 2195–2222.
- Rosenow F, Lüders H. Presurgical evaluation of epilepsy. Brain (2001). 124:1683–700.
Patents
- Nierenberg, Nicolas, Scott B. Wilson, and Mark L. Scheuer. United States Patent: 8972001 – Method and system for displaying data. 8972001, issued March 3, 2015. https://patents.google.com/patent/US8972001.
- ———. United States Patent: 9055927 – User interface for artifact removal in an EEG. 9055927, issued June 16, 2015. https://patents.google.com/patent/US9055927.
- ———. United States Patent: 9232922 – User interface for artifact removal in an EEG. 9232922, issued January 12, 2016. https://patents.google.com/patent/US9232922.
- ———. United States Patent: 10022091 – User interface for artifact removal in an EEG. 10022091, issued July 17, 2018. https://patents.google.com/patent/US10022091.
- Nierenberg, Nicolas, Scott Wilson, and Mark Scheuer. United States Patent: 8666484 – Method and system for displaying EEG data. 8666484, issued March 4, 2014. https://patents.google.com/patent/US8666484.
General References
- Hirsch, Lawrence J., Fong, Michael W.K., and Brenner, Richard P. Atlas of EEG in Critical Care. Second Edition. Wiley Blackwell, 2023.
- An updated, general reference with many cases illustrating the use of qEEG trends during cEEG monitoring, mostly using Persyst software.
- LaRoche, Suzette, and Haider, Hiba Arif, eds. Handbook of ICU EEG Monitoring. Second edition. New York: Demosmedical, Springer Publishing Company, 2018.
- A general reference with many figures illustrating the use of qEEG trends during ICU monitoring.
- Richard Brenner, and Mark Scheuer. Adult EEG, Second Edition DVD: An Interactive Reading Session. 2nd edition. New York: Demos Medical, 2013.
- An interactive teaching program featuring a set of carefully explained teaching cases in which qEEG trending is utilized.
- Scheuer, Mark L, and Scott B Wilson. “Data Analysis for Continuous EEG Monitoring in the ICU: Seeing the Forest and the Trees.” Journal of Clinical Neurophysiology: Official Publication of the American Electroencephalographic Society 21, no. 5 (n.d.): 353–78. doi:10.1097/01.WNP.0000147078.82085.D3
- Many people beginning to use qEEG find this article useful for general background information concerning some types of quantitative EEG assessments (e.g., aEEG, FFT spectrograms).
- Schomer, Donald L., and F. H. Lopes da Silva, eds. “EEG in the Intensive Care Unit: Anoxia, Coma, Brain Death, and Related Disorders.” In Niedermeyer’s Electroencephalography: Basic Principles, Clinical Applications, and Related Fields, Seventh edition., 610–58. New York, NY: Oxford University Press, 2018.
- This chapter, from a classic EEG text, contains many figures utilizing Persyst qEEG trending.